
The other day, I was updating the robots.txt file for a client’s website and thought this might be a good time to write an article about what it is and why it is important.
So, let me first begin by saying that within the expansive landscape of the World Wide Web, where millions of websites are competing to be found, maintaining control over how search engines interact with your website content is crucial. Among the most important tools that webmasters have at their disposal with respect to this interaction, is the robots.txt file. So, I would like to examine what a robots.txt file is, its significance and best practices for implementing it effectively.
What is a Robots.txt File?
In short, a robots.txt file can be best described as a plain text file that resides in a website’s root directory. This file provides instructions to web crawlers and search engine bots. These instructions tell search engine bots which parts (files) of a website, should be crawled and indexed, and which should not.
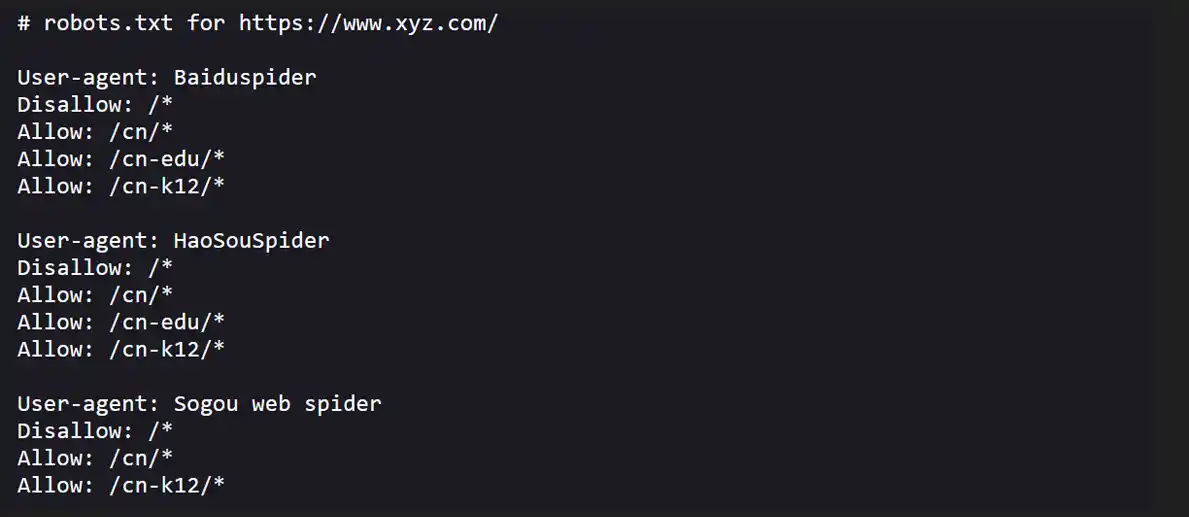
The typical format of a robots.txt file
A robots.txt file generally consists of two main parts:
User-Agent
This specifies which web crawler the following rules apply to. For instance, “User-agent: Googlebot” refers specifically to Google’s crawler.
Disallow/Allow Directives
These commands specify which directories or pages the bot should not access (disallow) or can access (allow). For example:
User-agent: *
Disallow: /private-directory/
Allow: /public-directory/
In the above example, all web crawlers (indicated by *) are told not to crawl any resources in /private-directory/, whereas they are free to access content in /public-directory/.

What makes a Robots.txt file Important?
It Establishes Crawling and Indexing Directives for A Given Website
A robots.txt file is the standard way in which website owners can designate which parts of their website they would like search engines to index. As such, this can be especially helpful when trying to prevent public access to sensitive content. Without this control, search engines might inadvertently index pages that could harm your search ranking or user experience.
It Helps to Conserve Server Resources
The process of crawling websites by search engine bots can consume bandwidth and web server resources. By restricting their access to specific files, unnecessary server resource usage can be mitigated. This in turn, makes crawling your website more efficient as bots only focus on the most important parts of your website.
It Improves SEO Strategies
Keeping certain pages off of the search engine index can enhance your overall SEO strategy. By preventing low-value pages from being indexed, you can help ensure that only high-quality content appears in search results, potentially improving your website’s rankings.
It Enhances Website Testing and Development
During the development phase of a website, webmasters can use the robots.txt file to prevent search engines from indexing their website until it is ready for public viewing.
Helpful Tips for Using Robots.txt
Using a robots.txt file correctly is important, so, here are a few things to keep in mind.
Be Specific
Use clear and specific directives in your robots.txt file. Avoid general disallow rules that might inadvertently block important content.
Test Your File
Use testing tools, like Google’s Robots Testing Tool, to ensure your directives are correctly implemented before going live. This can help prevent accidental issues where valuable pages are blocked.
Keep It Updated
Regularly review and update your robots.txt file as your website evolves. As new pages are added or removed, it’s important to adjust your directives accordingly.
Be Cautious with Disallows
Remember that while the robots.txt file instructs web crawlers, it is not a security mechanism. Sensitive information should not rely solely on a robots.txt file for protection.
Optimize Crawl Budget
For larger websites, consider optimizing usage of your crawl budget by indicating which sections are most important and should be crawled frequently.
So, there you have it. The robots.txt file is a powerful yet often overlooked component of a well-structured website. By strategically controlling which parts of your website are indexed by search engines, you can enhance your SEO efforts, conserve server resources and maintain the privacy of sensitive information.
 EMAIL US
EMAIL US